Quanda: A New Python Toolkit for Standardized Evaluation and Benchmarking of Training Data Attribution (TDA) in Explainable AI
0 comments
The Fraunhofer Institute for Telecommunications has put forth Quanda to bridge this gap. It is a Python toolkit that provides a comprehensive set of evaluation metrics and a uniform interface for seamless integration with current TDA implementations. This is user-friendly, thoroughly tested, and available as a library in PyPI. Quanda incorporates PyTorch Lightning, HuggingFace Datasets, Torchvision, Torcheval, and Torchmetrics libraries for seamless integration into users’ pipelines while avoiding reimplementing available features.
TDA evaluation in Quanda is comprehensive, beginning with a standard interface for many methods spread across independent repositories. It includes several metrics for various tasks that allow a thorough assessment and comparison. These standard benchmarks are available as precomputed evaluation benchmark suites to ensure user reproducibility and reliability. Quanda differs from its contemporaries, like Captum, TransformerLens, Alibi Explain, etc., in terms of the extensivity and comparability of evaluation metrics. Other evaluation strategies, such as downstream task evaluation and heuristics evaluation, fail due to their fragmented nature, single comparisons, and lack of reliability.
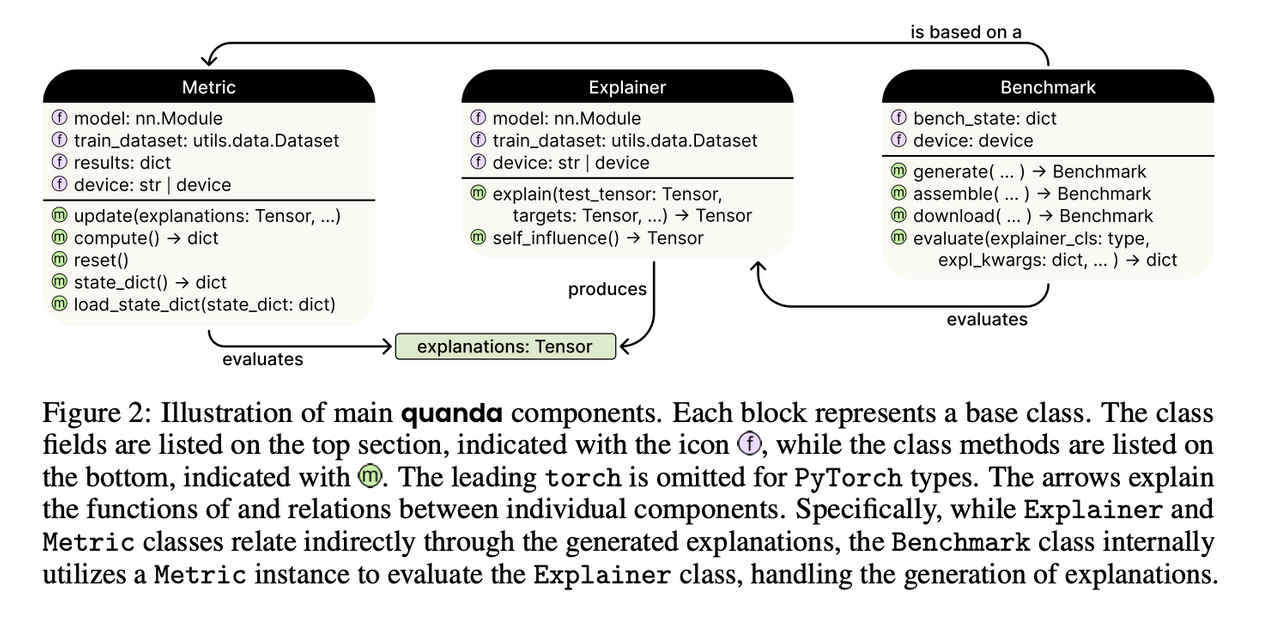
There are several functional units represented by modular interfaces in the Quanda library. It has three main components: explainers, evaluation metrics, and benchmarks. Each element is implemented as a base class that defines the minimal functionalities needed to create a new instance. This base class design permits users to evaluate even novel TDA methods by wrapping their implementation in accordance with the base explainability model.
Quanda is built on Explainers, Metrics, and Benchmarks. Each Explainer represents a specific TDA method, including its architecture, model weights, training dataset, and so on. Metrics summarize the performance and reliability of a TDA method in a compact form.Quanda’s stateful Metric design includes an update method for accounting for new test batches. Additionally, a metric can be categorized into three types: ground_truth, downstream_evaluation, or heuristic. Finally, Benchmark enables standard comparisons across different TDA methods.
An example usage of the Quanda library to evaluate concurrently generated explanations is given below:
Quanda addresses the gaps in TDA evaluation metrics that led to hesitancy in its adoption within the explainable community. TDA researchers can benefit from this library’s standard metrics, ready-to-use setups, and consistent wrappers for available implementations. In the future, it would be interesting to see Quanda’s functionalities extended to more complex areas, such as natural language processing.
Comments