SEC S20W2 || Databases and SQL language - Part 2
9 comments

Dear Steemians,
After a first week full of learning and discoveries about databases and SQL language, we are pleased to invite you to participate in the second week of the SEC S20W2 competition, which continues this exciting journey.
In this second part, we will dive deeper into the concepts introduced during the first week, focusing on the DQL (Data Query Language) and DML (Data Manipulation Language). While the first week laid a solid foundation on tables, relationships, and primary keys, this new phase will allow you to further explore SQL commands to query, insert, update, and delete data with ease.
This week is a logical continuation of the previous one but introduces more interactive and practical concepts in the world of databases. You will have the opportunity to apply what you’ve learned while discovering advanced techniques to manipulate your data more efficiently.
We invite you not to miss this opportunity to strengthen your knowledge and showcase your skills within the community. Get ready to face new challenges and share your results with everyone!
Good luck to all, and may this second week be as fruitful as the first!

Data Query and Manipulation Language (DQL+DML)
I. Data Query Language
- General Syntax
SQL is both a data manipulation language and a data definition language. However, data definition is typically managed by the database administrator, which is why most people using SQL primarily focus on the data manipulation language, specifically the data query language, which allows them to select the data they are interested in.
The main command in the data query language is the SELECT command.
The SELECT command is based on relational algebra, performing data selection operations on several relational tables through projection. Its general syntax is as follows:
SELECT [ALL] | [DISTINCT] <list of attributes> | * FROM <list of tables>
[WHERE <condition>]
[GROUP BY <list of attributes>] [HAVING <group condition>] [ORDER BY <list of sort attributes>];
SELECT: Specifies which columns or expressions should be returned by the query.
FROM: Specifies the tables involved in the query.
[...]: Content within brackets is optional.
The ALL option, as opposed to the DISTINCT option, is the default. It selects all rows satisfying the logical condition.
The DISTINCT option retains only distinct rows, eliminating duplicates.
The list of attributes specifies the selected attributes, separated by commas. When you want to select all columns from a table, you don’t need to enter the list of attributes. The * option performs this task.
The list of tables specifies all the tables (separated by commas) being queried.
The condition allows you to express complex qualifications using logical operators and arithmetic comparators.
2. Projection
A projection is an instruction that allows you to select a set of attributes from a table.
Syntax:
SELECT [ALL] | [DISTINCT] <list of attributes> | * FROM <the table>;
Examples:
- List all clients.
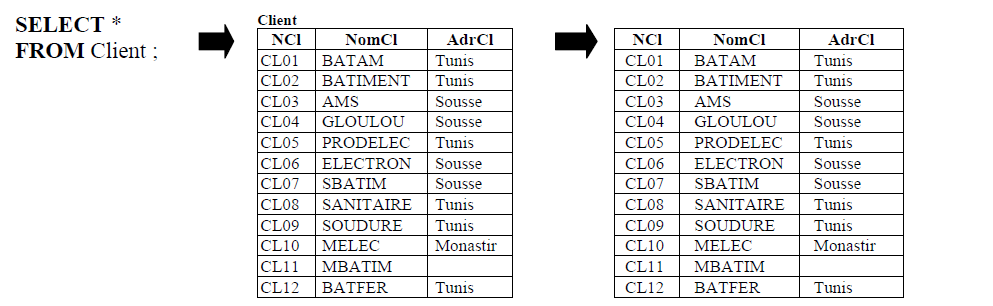
- List all products that have been ordered (only NP).
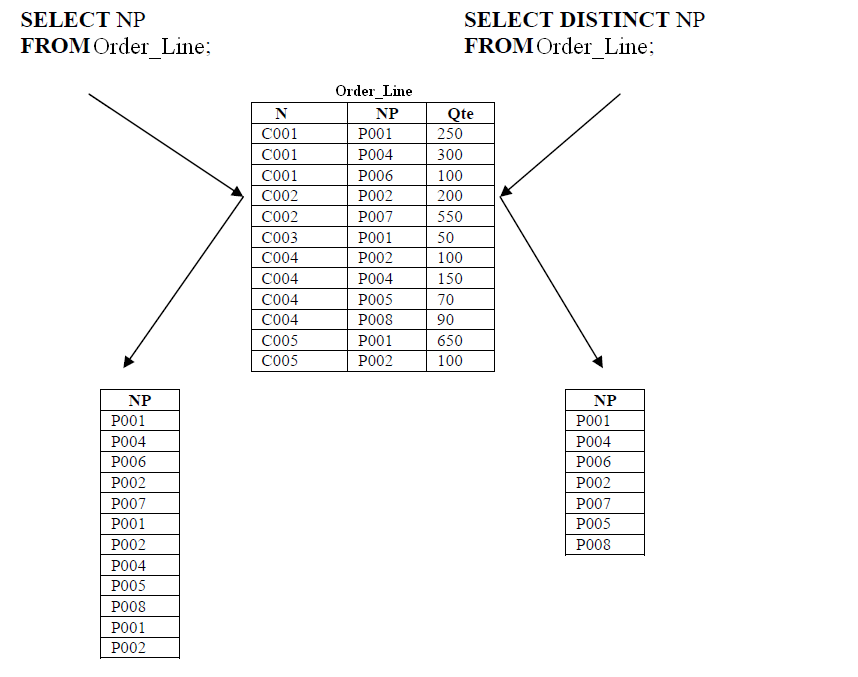
Note: DISTINCT is used to eliminate duplicates. By default, all tuples are retrieved (ALL).
3. Restrictions
A restriction selects rows that satisfy a logical condition applied to their attributes. In SQL, restrictions are expressed using the WHERE clause followed by a logical condition using logical operators (AND, OR, NOT), arithmetic operators (+, -, *, /, %), arithmetic comparators (=, !=, >, <, >=, <=), and predicates (NULL, IN, BETWEEN, LIKE, ...).
These operators apply to numeric values, character strings, and dates.
Note: Character strings and date constants must be enclosed in single quotes ('...'), unlike numbers.
Syntax:
SELECT [ALL] | [DISTINCT] <list of attributes> | * FROM <the table>
WHERE <condition>;
At the WHERE clause level, the following predicates apply:
- WHERE exp1 = exp2: True if both expressions exp1 and exp2 are equal.
- WHERE exp1 <> exp2: True if expressions exp1 and exp2 are different.
- WHERE exp1 < exp2: True if exp1 is less than exp2.
- WHERE exp1 > exp2: True if exp1 is greater than exp2.
- WHERE exp1 <= exp2: True if exp1 is less than or equal to exp2.
- WHERE exp1 >= exp2: True if exp1 is greater than or equal to exp2.
- WHERE exp1 BETWEEN exp2 AND exp3: True if exp1 is between exp2 and exp3, inclusive.
- WHERE exp1 LIKE exp2: True if substring exp2 is present in exp1.
- WHERE exp1 NOT LIKE exp2: True if substring exp2 is not present in exp1.
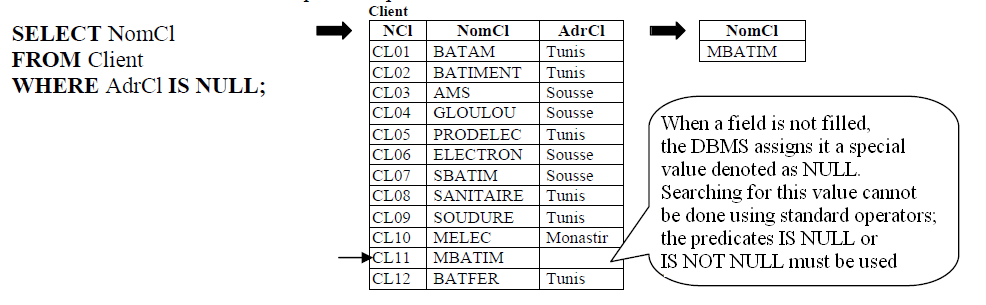
- WHERE exp1 IS NULL: True if exp1 is null.
- WHERE exp1 IS NOT NULL: True if exp1 is not null.
Examples:
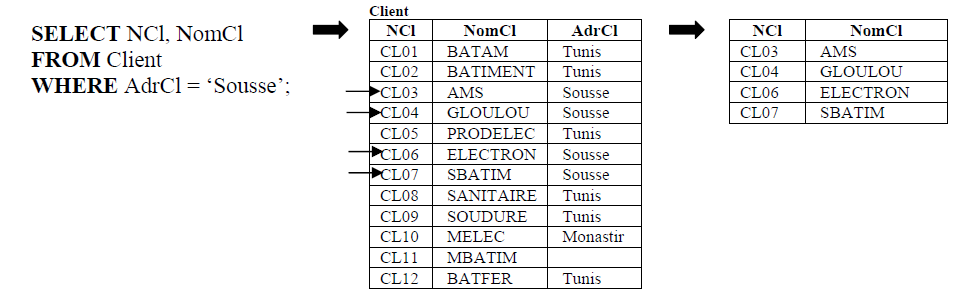
- List the number and name of clients from the city of Sousse.
- List orders with dates later than ‘01/01/2004’.

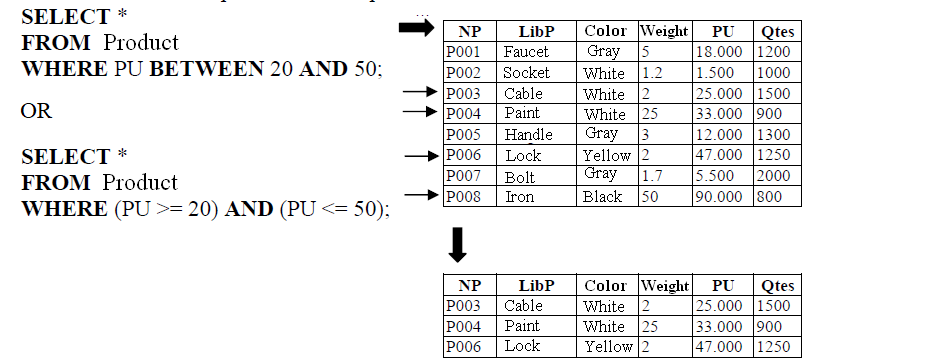
- List products with prices between 20 and 50.
- List clients whose names start with 'B'.
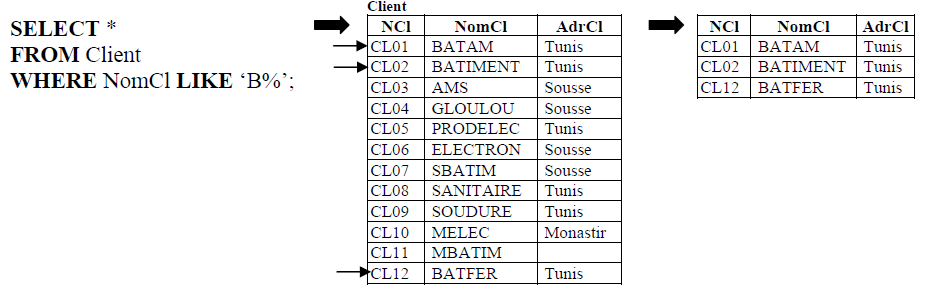
Note: The LIKE predicate allows string comparisons using wildcard characters:
- The % character replaces a sequence of characters (including null).
- The _ character replaces a single character.
- Characters in brackets [-] define a character range (e.g., [J-M]).
To select clients whose names have an 'E' in the second position:
WHERE ClientName LIKE "_E%"
Provide the names of customers who do not have an address.
4. Expressions, Aliases, and Functions
a. Expression
SQL expressions work with attributes, constants, and functions. Arithmetic operators can link these elements (+, -, *, /). Expressions can appear:
- As result columns of a SELECT statement.
- In a WHERE clause.
- In an ORDER BY clause.
- In data manipulation commands (INSERT, UPDATE, DELETE).
b. Alias
Aliases allow renaming attributes or tables.
SELECT attr1 AS alias1, attr2 AS alias2, ...
FROM table1 alias t1, table2 alias t2…;
For attributes, the alias corresponds to the column titles in the query result. It is often used for calculated attributes (expressions).
Note: The AS keyword is optional.
c. Function
The following table lists some predefined functions:
| Function Name | Function Role |
|---|---|
| AVG | Average |
| SUM | Sum |
| MIN | Minimum |
| MAX | Maximum |
| COUNT(*) | Number of rows |
| COUNT(Attr) | Number of non-null values for the attribute |
| COUNT([DISTINCT] Attr) | Number of distinct non-null values for the attribute |
Application:
Provide the value of products in stock.
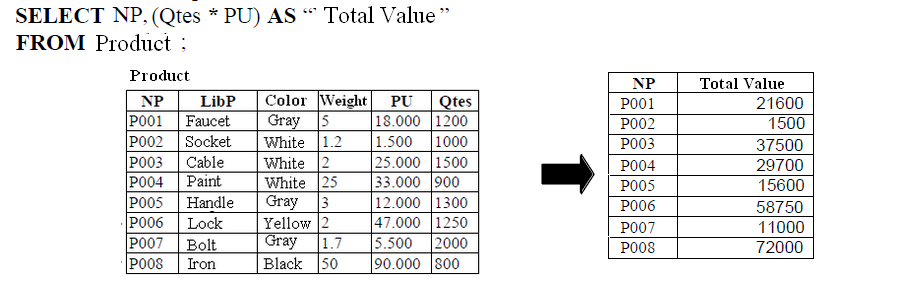
We can express this query without specifying the keyword AS:
SELECT NP, (Qtes * PU) "Total Value"
FROM Product;
We only put the result column names in quotes if they contain spaces:
SELECT NP, (Qtes * PU) Value
FROM Product;
In both queries, NP refers to the product name, Qtes to the quantity, and PU to the unit price. The first query uses quotes because "Total Value" contains a space, while the second query does not require quotes as the column name "Value" does not have any spaces.
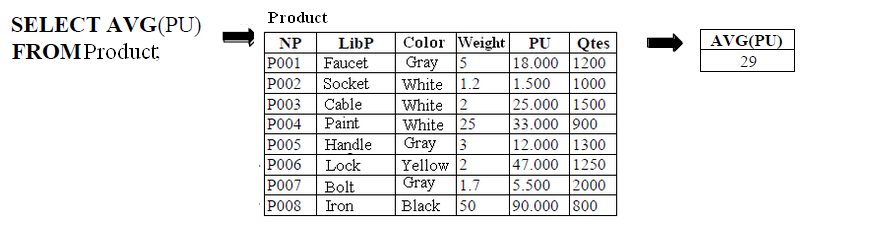
Provide the average unit price of the products.
5. Selection with Join
This involves selecting data from multiple tables that have one or more common attributes. The join is performed through conditions specified in the WHERE clause.
Syntax:
SELECT [ALL] | [DISTINCT] <list of attributes> | * FROM <list of tables>
WHERE Table1.Attrj = Table2.Attrj AND …
AND <condition>;
Examples:
- List the product names for order number 'C002'.
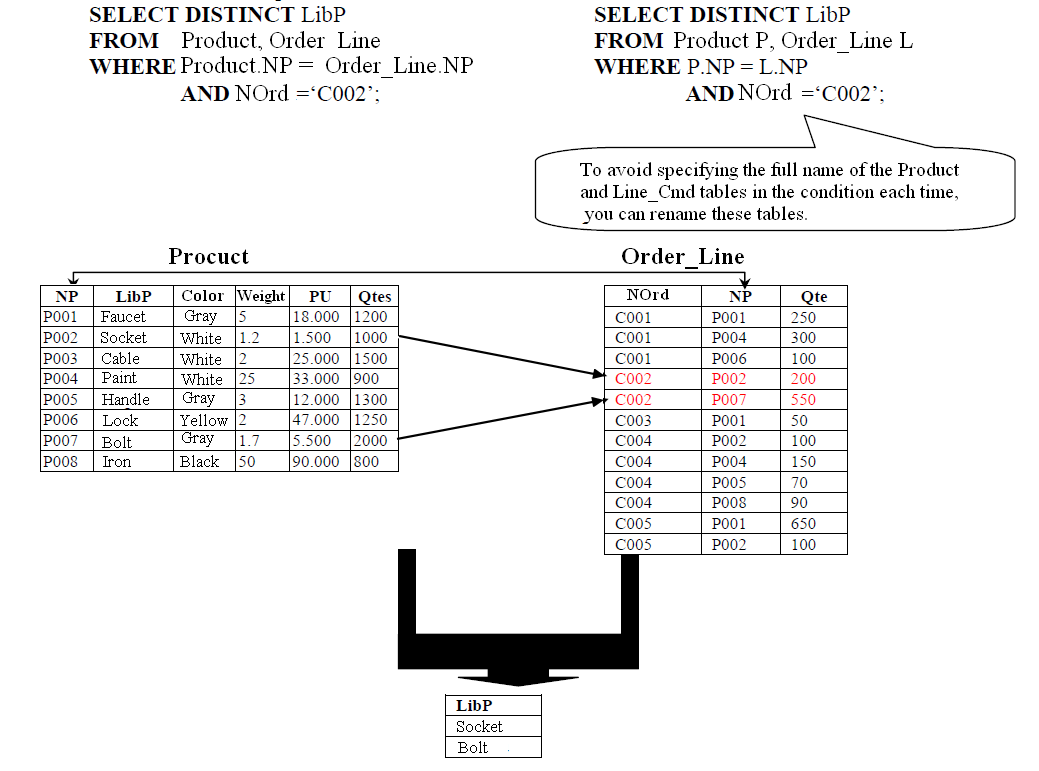
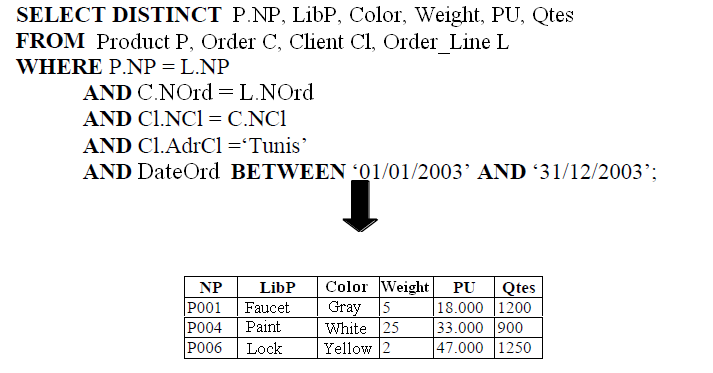
- List all products ordered in 2003 and sold to clients in Tunis.
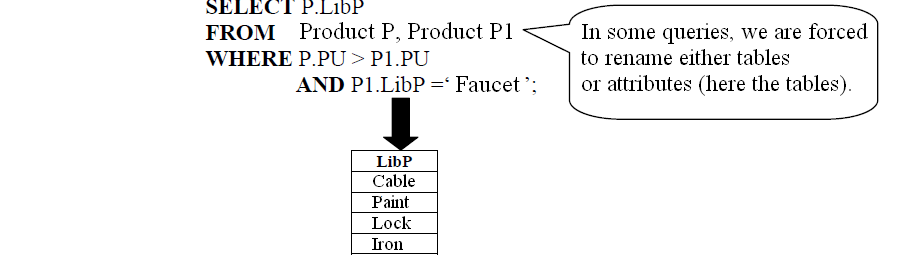
- List the names of products with a unit price greater than that of the product 'Faucet'.
6. Grouping
It is possible to group rows with a common value using the GROUP BY clause and group functions (cf. Function).
Syntax:
SELECT Attr1, Attr2, ..., GroupFunction FROM Table1, Table2, ...
WHERE List_Condition
GROUP BY List_Group
HAVING Condition;
- The GROUP BY clause, followed by the name of each attribute, defines the groups.
- The HAVING clause works in conjunction with GROUP BY to apply a restriction on the created groups.
Note: Aggregate functions used alone in a SELECT statement (without GROUP BY) operate on the entire set of selected tuples as if there were only one group.
Examples:
- Count the number of orders per client.

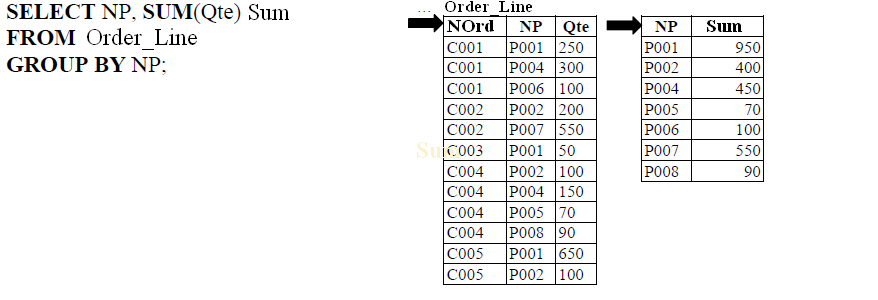
- Total quantity ordered per product.
- Total amount per order.
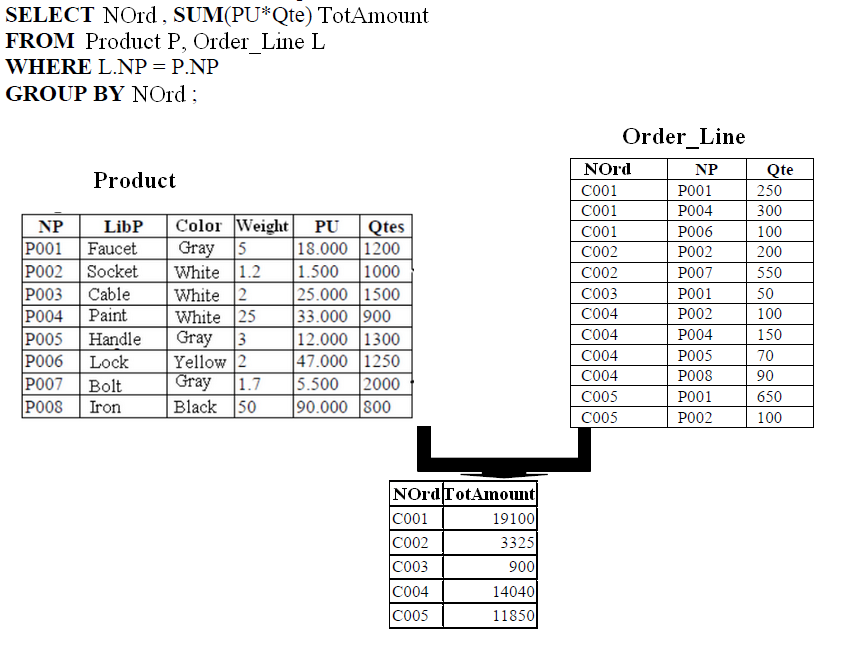
7. Sorting
The result rows of a SELECT statement are returned in an arbitrary order. The ORDER BY clause specifies the order in which the selected rows should be returned.
Syntax:
SELECT Attr1, Attr2, ..., Attrn FROM Table_Name1, Table_Name2, ...
WHERE Condition_List
ORDER BY Attr1 [ASC|DESC], Attr2 [ASC|DESC], ...;
Note: The default sort order is ascending (ASC).
Example:
- List client names in descending order.
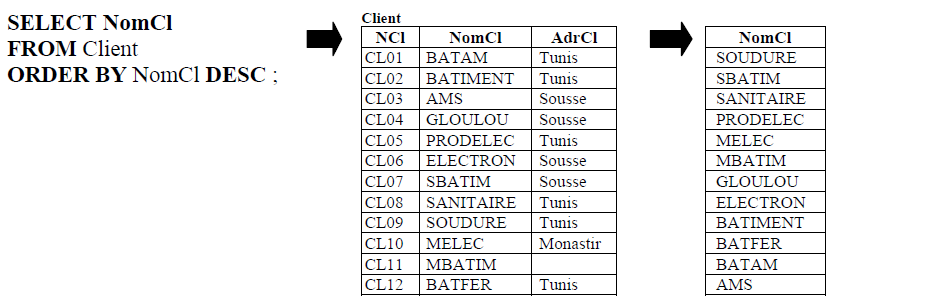
II. Data Manipulation Language (DML)
The Data Manipulation Language (DML) consists of commands for querying and updating data in tables. Updating includes inserting new data, modifying existing data, and deleting data.
1. Inserting Data
Data can be inserted in two ways:
- Inserting a single row: The row contains values passed as parameters in the parentheses following the VALUES clause.
Syntax:
INSERT INTO Table_Name (Attr1, Attr2, ...)
VALUES (Value1, Value2, ...);
Example:
- Populate the
Clienttable:
INSERT INTO Client VALUES ('CL01', 'BATAM', 'Tunis');
INSERT INTO Client VALUES ('CL02', 'BATIMENT', 'Tunis');
- Inserting multiple rows: It's possible to add multiple rows to a table in a single query using the following syntax:
Syntax:
INSERT INTO Table_Name (Attr1, Attr2, ...)
VALUES (Value1a, Value1b, ...), (Value2a, Value2b, ...), ...;
Example:
- Populate the
Clienttable:
INSERT INTO Client (ClientID, ClientName, ClientAddress)
VALUES ('CL03', 'AMS', 'Sousse'),
('CL04', 'GLOULOU', 'Sousse'),
('CL05', 'PRODELEC', 'Tunis');
Note: Any omitted attributes will take the default value of NULL. Data is assigned to columns in the order the attributes are declared in the INTO clause.
2. Modifying Data
Using the UPDATE command, you can modify the values of one or more fields in existing rows of a table.
Syntax:
UPDATE Table_Name
SET Attr1 = Expr1, Attr2 = Expr2, ...
WHERE Condition;
Examples:
- Change the weight of product number 'P002' to 1:
UPDATE Product
SET Weight = 1
WHERE ProductID = 'P002';
- Increase the stock quantity of all products by 10%:
UPDATE Product
SET Quantity = 1.1 * Quantity;
3. Deleting Data
The DELETE command is used to remove rows from a table.
Syntax:
DELETE FROM Table_Name
WHERE Condition;
Here, the FROM clause specifies the table from which rows will be deleted, and the WHERE clause defines the criteria for the rows to be deleted.
Homework :
Exercise 1:
A) For each row presented in the table below, extract the outlier element and provide a brief description of the common point between the remaining three elements. (1 point)
| Element 1 | Element 2 | Element 3 | Element 4 | Outlier | Common Point |
|---|---|---|---|---|---|
| Update | Select | Alter | Insert | ||
| Max | Desc | Sum | Avg | ||
| Between | In | Count | Like | ||
| Primary key | Foreign key | Unique | Distinct |
B) Answer TRUE or FALSE to the following statements: (1 point)
| Affirmations | True/False |
|---|---|
| 1. In SQL, it is not possible to delete a table that contains tuples. | |
| 2. A DBMS ensures data redundancy. | |
| 3. The Data Definition Language (DDL) allows adding integrity constraints to a table. | |
| 4. A primary key in one table can be a primary key in another table. | |
| 5. In SQL, the ORDER BY clause is used to sort selected columns of a table. | |
| 6. A foreign key column can contain NULL values. | |
| 7. The PRIMARY KEY constraint includes both UNIQUE and NULL constraints. | |
| 8. Referential integrity constraints ensure links between tables in a database. |
Exercise 2:
Given the following tables of books and members:
| Id | Title | Author | Publisher | Pages | Year | Borrower | Return_Date |
|---|---|---|---|---|---|---|---|
| 1 | Notre-dame de Paris | Victor Hugo | Gosselin | 636 | 1831 | 1 | 2014-05-13 |
| 2 | Les Misérables | Victor Hugo | Lacroix | 1662 | 1862 | 2 | 2014-08-28 |
| 3 | Journey to the Center of the Earth | Jules Verne | Hetzel | 1864 | 1 | 2014-07-10 | |
| 4 | Around the World in 80 Days | Jules Verne | Hetzel | 223 | 1872 | 1 | 2014-06-10 |
| 5 | House of the Dead | Fyodor Dostoevsky | Mikhail | 1276 | 1862 | 2 | 2014-05-13 |
Table 1: Books
| Id | Last Name | First Name | |
|---|---|---|---|
| 1 | DUPONT | Jean | [email protected] |
| 2 | MARTIN | Paul | [email protected] |
Table 2: Members
- Fill in the table below by providing the result returned or the query to obtain the result: (1 point)
| Query | Result |
|---|---|
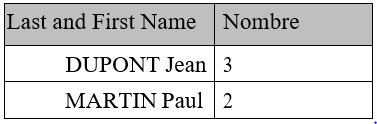
| SELECT count(Pages) "Count", sum(Pages) "Total Pages" FROM books | |
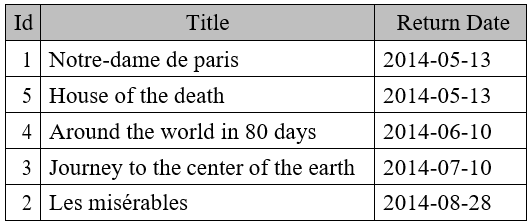 | |
| SELECT * FROM books WHERE Year IN (SELECT Year FROM books WHERE Id=2) AND Id<>2 | |
 |
- For each of the following propositions, validate each answer by marking the box with V for true or F for false. (1.5 points)
a) By executing the SQL query: UPDATE books SET Title = "Title1"; the DBMS:
□ Modifies the Title field of the first record in the books table to Title1.
□ Modifies the Title field of all records in the books table to Title1.
□ Displays an error message due to the absence of the WHERE clause.
b) The SQL query:
SELECT Title FROM books WHERE MONTH(Return_Date) in (5,6) AND YEAR(Return_Date) = 2014; is equivalent to:
□ SELECT Title FROM books WHERE Return_Date between "2014-05-01" AND "2014-06-30";
□ SELECT Title FROM books WHERE Return_Date >= "2014-05-01" OR Return_Date <= "2014-06-30";
□ SELECT Title FROM books WHERE Return_Date between "2014-05-01" OR "2014-06-30";
c) By executing the SQL query: SELECT Author, count(*) FROM books GROUP BY Title; the DBMS:
□ Displays the number of authors per title.
□ Displays the number of books per author.
□ Does not work.
d) By executing the SQL query: DELETE FROM books WHERE Pages = Null; the DBMS:
□ Deletes the Pages column.
□ Deletes the rows where the page count is not provided.
□ Does not work.
Exercise 3: (5.5 points)
Consider the medical laboratory database "analysis" defined by the following simplified textual representation:
PATIENT (idPatient, last_name, first_name, age, city)
The Patient table contains all the patients who have undergone analyses in the laboratory.
- idPatient: patient identifier (string), primary key
- last_name: patient’s last name (string)
- first_name: patient’s first name (string)
- age: patient’s age (integer)
- city: patient’s city (string)
ANALYSIS (idAnalysis, name, price, min_value, max_value)
The Analysis table contains all the analyses the lab can perform.
- idAnalysis: analysis identifier (string), primary key
- name: name of the analysis (string)
- price: analysis price (decimal)
- min_value: minimum usual value (decimal)
- max_value: maximum usual value (decimal)
DOCTOR (idDoctor, last_name, city, specialty)
The Doctor table contains all currently practicing doctors recorded in the database.
- idDoctor: doctor identifier (string), primary key
- last_name: doctor’s last name (string)
- city: doctor’s city (string)
- specialty: doctor’s specialty (string)
REPORT (idReport, idDoctor#, idPatient#, date)
The Report table contains patient analysis reports.
- idReport: analysis report identifier (integer), primary key
- idPatient: patient identifier (string)
- idDoctor: doctor identifier (string)
- date: analysis report date (date format: YYYY-MM-DD)
RESULT_REPORT (idReport#, idAnalysis#, value, status)
The ResultReport table contains the results of the analysis reports.
- idReport: analysis report identifier (integer)
- idAnalysis: analysis identifier (string)
- value: a value representing the analysis result (decimal)
- status: a character ('N' for normal, 'H' for high, 'L' for low) representing the analysis result status
Write the SQL queries to:
- Determine the IDs, last names, and first names of patients who have undergone 'Cholesterol' analyses, sorted in ascending order by last names and first names.
- Determine the names of patients who have undergone analyses prescribed by the doctor with ID 'DR2015' and who are not from his/her city.
- Determine the date when the patient with ID 'PA161' had their last analysis report.
- Retrieve all information related to the analysis results of the patient with ID 'PA170' performed on March 12, 2018.
- Update the status of analysis results to 'L' for the analyses with IDs 'AnChol12' and 'AnGlug15' for the report with ID 2020.
- Find the report IDs and patient IDs with at least two abnormal analysis results per report.
- Count the number of reports per doctor living in the city of Sousse.
- Retrieve the IDs, last names, first names, and cities of patients aged between 20 and 40 years who have had more than five analyses after May 26, 2015.
- Delete analyses with no name.
Contest Guidelines
Post can be written in any community or in your own blog.
Post must be #steemexclusive.
Use the following title: SEC S20W2 || Databases and SQL language - Part 2
Participants must be verified and active users on the platform.
Post must be more than 350 words. (350 to 500 words)
The images used must be the author's own or free of copyright. (Don't forget to include the source.)
Participants should not use any bot voting services, do not engage in vote buying.
The participation schedule is between Monday, September 16 , 2024 at 00:00 UTC to Sunday, - September 22, 2024 at 23:59 UTC.
Community moderators would leave quality ratings of your articles and likely upvotes.
The publication can be in any language.
Plagiarism and use of AI is prohibited.
Participants must appropriately follow #club5050 or #club75 or #club100.
Use the tags #dynamicdevs-s20w2 , #country (example- #tunisia, #Nigeria) #steemexclusive.
Use the #burnsteem25 tag only if you have set the 25% payee to @null.
Post the link to your entry in the comments section of this contest post. (very important).
Invite at least 3 friends to participate in this contest.
Strive to leave valuable feedback on other people's entries.
Share your post on Twitter and drop the link as a comment on your post.
Your article must get at least 10 upvotes and 5 valid comments to count as valid in the contest, so be sure to interact with other users' entries
Rewards
SC01/SC02 would be checking on the entire 16 participating Teaching Teams and Challengers and upvoting outstanding content. Upvote is not guaranteed for all articles. Kindly take note.
At the end of the week, we would nominate the top 5 users who had performed well in the contest and would be eligible for votes from SC01/SC02.
Important Notice: The selection of the five should be based solely on the quality of their post. Number of comments is no longer a factor to be considered.
Best Regards,
Dynamic Devs Team

Comments